最近在看Python爬虫,看了知乎讨论和崔同学的系列教程,想试一试效果,于是拿查成绩来演示。“成品”效果:

首先我得知道登录的地址,于是使用Chrome开发者工具查看哪个地址是Post的,打开查成绩网页登录,发现地址是 http://cjcx.jlu.edu.cn/score/action/security_check.php
查看Header,发现POST的内容有一个是教学号,一个字符串,我猜是密码MD5之后的字符串:
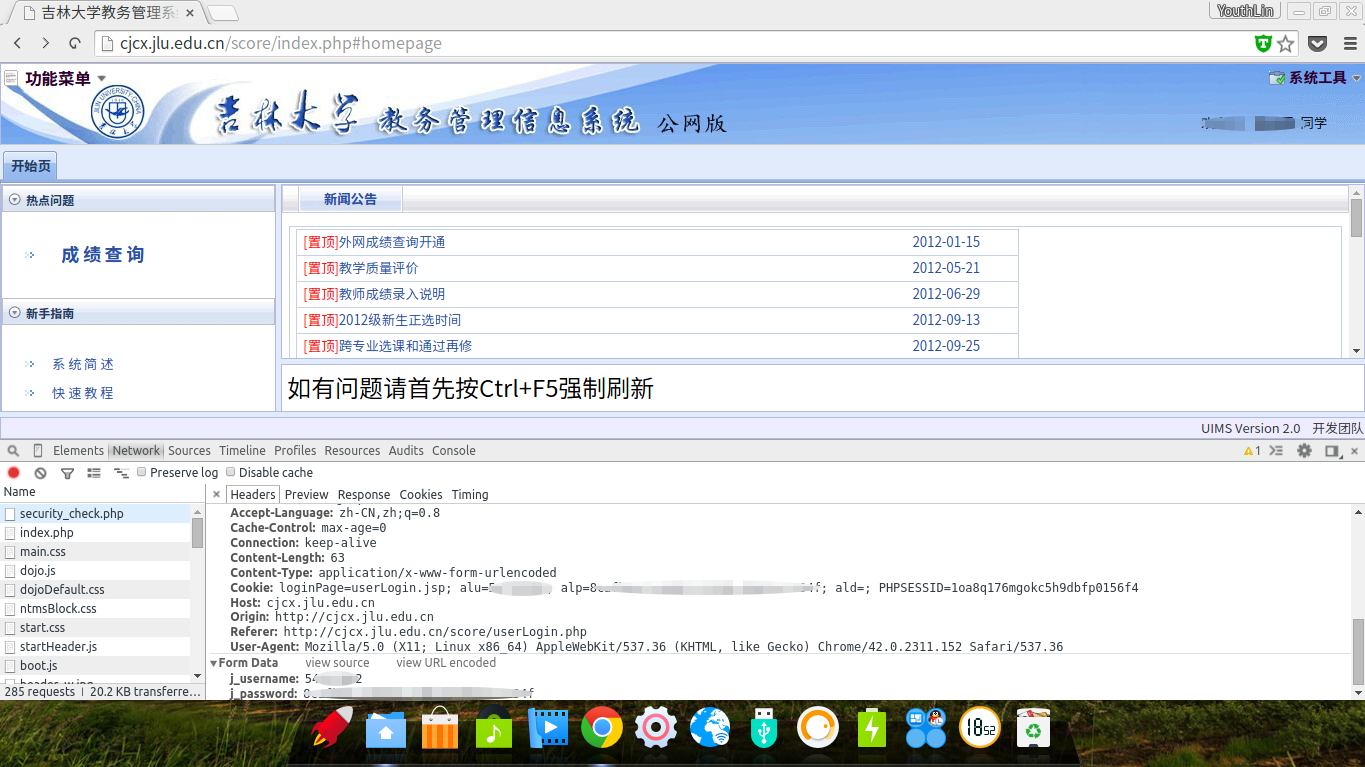
看源代码,找到了:
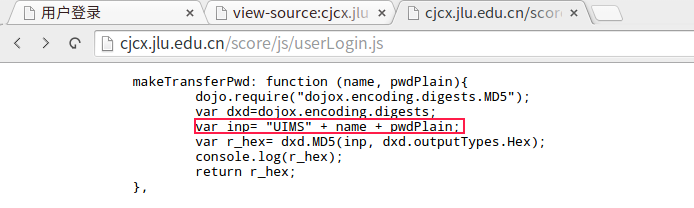
原来是’UIMS[stuid][passwd]’这个字符串MD5之后作为参数j_password和教学号一起Post。
在网页上登录,登录成功的话跳转到新的地址,否则还是返回登录页。
刚开始没考虑登录失败的情况,毕竟是用我自己的账号登录的,当然登录成功了,后来考虑到可能账号密码错误,于是加上了判断条件。
怎么判断呢,我突然发现登录页和登录成功后的主页HTML源代码的开头不一样:登录页是<html ....开头,登录成功的主页是<!DOCtype...开头,233333于是可用如下代码来判断。
temp = result.read()
#登录成功返回的页面开头是<!Doctype ...
#登录失败返回的页面开头是<html>...
if temp[1] == '!':
print u'登录成功'
else:
#失败
在F12开发者工具里看到有Cookies,于是post登录时需要带上cookie,就是构建辣个opener时带上cookie就好了,之后它会自动带上。
登录成功后就是查成绩啦,点击成绩查询页面的按钮继续跟踪post数据,发现了查成绩了网址是另一个:http://cjcx.jlu.edu.cn/score/action/service_res.php
进一步分析发现post给它的数据不同返回的结果也不同,而且post数据和返回的结果都看起来是json格式的……
崔同学的教程里没讲json怎么处理啊,怎么办不会了。。。好吧,万能的搜索引擎出场了。我搜到了怎么把数据变成json格式然后post出去,和怎么解析返回的json数据。喜大普奔。
post数据是类似这样的:
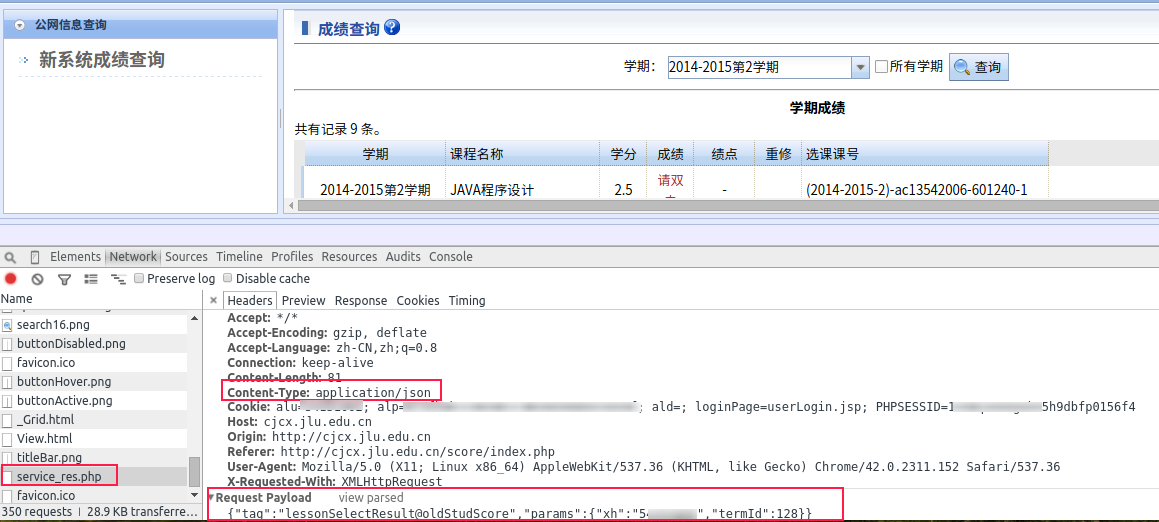
data = json.dumps({
"tag":"lessonSelectResult@oldStudScore",
"params":{
"xh":self.stuid,
"termId":termId #不指定学期则返回所有学期成绩
}
})
tag就是这样的一个字符串,params是教学号和学期的ID,如果不指定学期ID就会返回所有学期的成绩
可是怎么获取学期的ID呢,虽然我现在只对2014-2015-2学期的成绩感兴趣,它的Id是128,但我也想能够查询以前的成绩,于是需要获取所有学期的ID
data = json.dumps({
"type":"search",
"res":"teachingTerm",
"orderBy":"termId desc",
"tag":"teachingTerm"
})
这样子post他就会返回包含所有学期Id的json数据了,把ID和对应的学期输出,让用户选择学期,然后把选择的哪个ID作为参数post出去就能返回这个学期的成绩了。
返回的成绩数据是类似这样的:
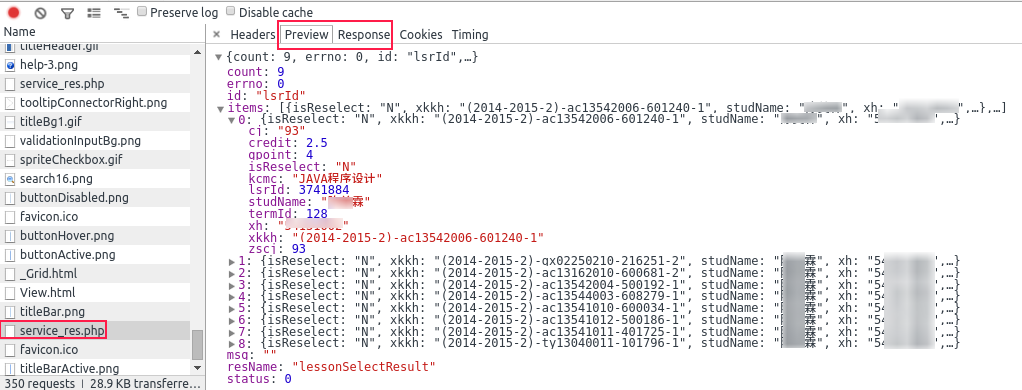
{
"count": 9, //item个数
"errno": 0, //不知道
"id": "lsrId",//不知道
"items": [
{
"isReselect": "N", //是否是重修
"xkkh": "(2014-2015-2)-ac13542006-601240-1", //选课课号
"studName": "姓名", //姓名
"xh": "xxxx", //教学号
"lsrId": 3741884, //不知道
"cj": "93", //成绩:字符串
"gpoint": 4, //绩点:浮点数
"zscj": 93, //成绩:浮点数
"credit": 2.5, //学分:浮点数
"kcmc": "JAVA程序设计", //课程名称
"termId": 128 //学期ID
},
{...},
...
{...}
"msg": "", //可能是错误信息
"resName": "lessonSelectResult", //不知道
"status": 0 //非0好像表示出错
}
//一个json在线校验 http://www.bejson.com/
接下来就是处理这个json了:
#json处理: http://blog.chinaunix.net/uid-21961132-id-2915452.html
if j['count'] == 0:
print u'没有查到符合条件的记录',
print j['msg'],'\n'
#exit(0)
#continue
print j['items'][0]["studName"]
print u'课程名称\t成绩\t学分\t绩点\t重修\t选课课号'
for item in j['items']:
#格式化输出:http://www.cnblogs.com/plwang1990/p/3757549.html
print "%-7s\t%2s\t%.1f\t%.1f\t%-4s %-32s" % (item["kcmc"][:7],item["cj"],item["credit"],item["gpoint"],item["isReselect"],item["xkkh"][:30])
print ''
json的对象,也就是{}里的内容当做字典,使用j['count']的方式访问,把数组,也就是[]里的内容当做列表,所以有j['items'][0]表示第一个item,里面又是一个字典。
然后输出的内容有6项,刚开始我想用+连接字符串,加上'\t',这个字符串就好长了,竟然报错,说什么需要缓冲区。。。好吧换成用格式化输出,还更好顺便解决了输出的样式,%-7s表示左对齐至少占7个字符位置。课程名称有的太长了,我就给截取了:item['kcmc'][:7]表示截取前7个元素。
差不多就是这样的功能,然后完善一下,做成循环,把输入密码那块改成了不显示密码,满满的Linux风格~md5加密网上一搜就有使用方法
不过还有一个问题啊啊啊啊,raw_input()里不能用u字符串,结果就是在瘟到死(Windows)下显示中!文!乱!码!
搜了一上午还是不知道怎么解决,,那个''.decode('utf-8').encode('gb2312')的可以解决raw_input(),但解决不了getpass.getpass('')啊,正当我想放弃时,(比如使用英文提示输入?但是教学号怎么表示,奇葩的是我们有个学号有个教学号,这里要用教学号),我突然想到,可以只用print u'提示内容’输出提示,raw_input()和getpass()里不输出内容,哈哈哈哈哈我真是天才23333(print '',)后面加个逗号就不会换行
贴上完整代码:(点击展开)
# -*- coding:utf-8 -*-
__author__ = 'Youth.Lin'
__date__ = u'2015年 07月 26日 星期日 17:07:53 CST'
import urllib
import urllib2
import cookielib
import json
import hashlib
#import os
#终端输入密码: http://www.cnblogs.com/lovebread/archive/2010/11/09/1872774.html
import getpass
#鸣谢: http://cuiqingcai.com/1052.html
class JLUcjcx:
#构造函数
def __init__(self,stu_id,j_passwd):
#登录URL
self.loginUrl = 'http://cjcx.jlu.edu.cn/score/action/security_check.php'
#查成绩URL
self.cjcxUrl = 'http://cjcx.jlu.edu.cn/score/action/service_res.php'
self.cookies = cookielib.CookieJar()
self.stuid = stuid
self.postdata = urllib.urlencode({
'j_username':self.stuid,
'j_password':j_passwd
})
self.request = urllib2.Request('')
#self.termIdInfo = []
#构建opener
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookies))
def getTermId(self):
self.request = urllib2.Request(
url = self.cjcxUrl,
#json的Post方式: http://blog.chinaunix.net/uid-26000296-id-4394470.html
data = json.dumps({
"type":"search",
"res":"teachingTerm",
"orderBy":"termId desc",
"tag":"teachingTerm"
})
)
#必须加上这一句:
self.request.add_header('Content-Type','application/json')
result = self.opener.open(self.request)
j = json.loads(result.read())
print u'ID\t学期\t\t\tID\t学期'
i=0
for item in j['items']:
#self.termIdInfo.append({item['termId'],item['termName']})
print '%d\t%s%c' % (item['termId'],item['termName'],"\t\n"[i%2]),
i += 1
print u'\n请输入要查询的学期的ID,输入0查询所有学期,输入-1退出:',
return input()
def login(self):
self.request = urllib2.Request(
url = self.loginUrl,
data = self.postdata
)
self.request.add_header('User-Agent','Python JLUcjcx By Youth.霖')
result = self.opener.open(self.request)
temp = result.read()
#登录成功返回的页面开头是<!Doctype ...
#登录失败返回的页面开头是<html>...
if temp[1] == '!':
print u'登录成功!'
return True
else:
print u'登录失败:可能是用户名或密码错误,或者服务器当前不可用'
return False
#成员函数:返回成绩json
def getResult(self):
termId = self.getTermId()
print ''
if termId > 0:
self.request = urllib2.Request(
url = self.cjcxUrl,
data = json.dumps({
"tag":"lessonSelectResult@oldStudScore",
"params":{
"xh":self.stuid,
"termId":termId #不指定学期则返回所有学期成绩
}
})
)
elif termId == 0:
self.request = urllib2.Request(
url = self.cjcxUrl,
data = json.dumps({
"tag":"lessonSelectResult@oldStudScore",
"params":{
"xh":self.stuid,
#"termId":termId #不指定学期则返回所有学期成绩
}
})
)
else:
exit(0)
self.request.add_header('Content-Type','application/json')
result = self.opener.open(self.request)
return result.read()
def ui(self):
logined = cjcx.login()
#登录失败,退出
if logined == False:
exit(1)
while True:
temp = cjcx.getResult()
j = json.loads(temp)
#json处理: http://blog.chinaunix.net/uid-21961132-id-2915452.html
if j['count'] == 0:
print u'没有查到符合条件的记录',
print j['msg'],'\n'
#exit(0)
continue
print j['items'][0]["studName"]
print u'课程名称\t成绩\t学分\t绩点\t重修\t选课课号'
for item in j['items']:
#格式化输出:http://www.cnblogs.com/plwang1990/p/3757549.html
print "%-7s\t%2s\t%.1f\t%.1f\t%-4s %-32s" % (item["kcmc"][:7],item["cj"],item["credit"],item["gpoint"],item["isReselect"],item["xkkh"][:30])
print ''
#暂停: http://tieba.baidu.com/p/115368991
#os.system('pause')
print u'\n回车继续:',
aaa = raw_input()
print ''
#--------------------------------------------------------------------------
print u'==========吉林大学教务管理系统--成绩查询=========='
print u' ===== Youth.霖 ====='
print u'========== https://youthlin.com =========='
print u'请输入教学号:',
stuid = raw_input('')
print u'请输入密码(密码不会显示,输入完成后回车):',
passwd = getpass.getpass('')
#passwd = raw_input('请输入密码:')
#密码默认是身份证后6位,01-09月由0开头,
#如果使用imput()输入则会解析成非十进制数字,所以使用raw_input()
#md5加密: http://my.oschina.net/duhaizhang/blog/67214
m = hashlib.md5()
#字符串连接: http://zhidao.baidu.com/question/402827712.html
#另: ''.join(['foo','bar',a,b,...])
m.update("UIMS%s%s"%(stuid,passwd))
j_passwd = m.hexdigest()
cjcx = JLUcjcx(stuid,j_passwd)
cjcx.ui()
最后贴上使用界面:
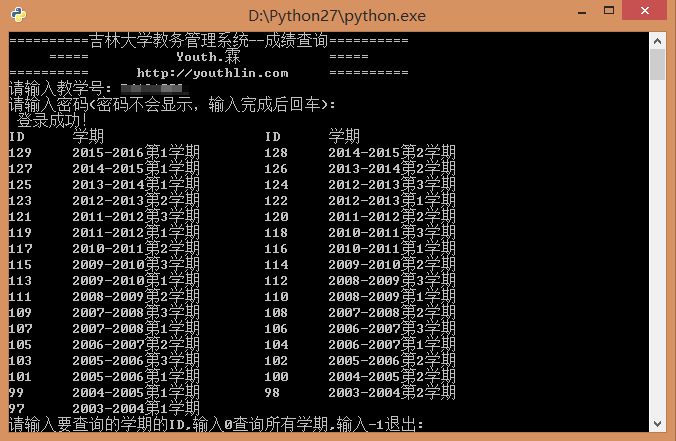
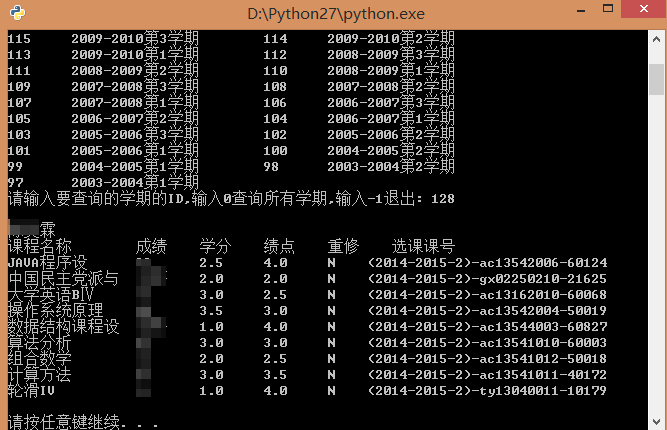
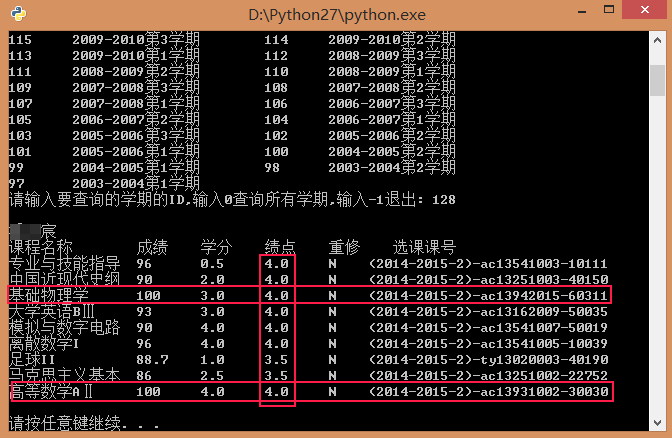
再来一张学神的成绩:
(别问我怎么有学弟的账号密码,好好学习就对了,下图就是榜样啊!)
PS:附源代码下载链接: http://pan.baidu.com/s/1hqGns5u 密码: 9n4v
因为Python对缩进真是变态的要求严格
声明
- 本作品采用署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。除非特别注明, 霖博客文章均为原创。
- 转载请保留本文(《Python写的吉大公网版成绩查询》)链接地址: https://youthlin.com/?p=1049
- 订阅本站:https://youthlin.com/feed/
“Python写的吉大公网版成绩查询”上的13条回复
曾经住北一的路过~
最近也想爬uims,但是看博主的思路到userlogin.js那个密码的加密方式那里进行不下去了。md5的加密方式现在应该是可用的,但是我不知道上哪里找它的源码。
在下医学生,不是程序猿,望赐教
这个是公网的成绩查询,不是内网的 uims.
找源码可以使用 Chrome 浏览器(Chrome|Firefox 会比 XX 高速浏览器更有优越感233) Ctrl+U 看源代码,F12 看 Network 栏加载的内容。
uims 登录你可以参考现成的代码:https://github.com/yaalsn/JLU_Uims
嗯我现在就在公网上找
我用的是360极速,chrome内核的,因为习惯了鼠标手势,但是F12功能是一样的呀
嗯刚才找到了。一直不会打开js的源码,刚刚试出来了,终于搜到了。
你的github我很早以前就光顾过啦,躺收藏夹里面很久了。我还是个初学者,想自己造轮子锻炼自己,所以才想重写一遍登陆uims的代码的~
谢谢指点啦
这个链接是我同学的 不是我的![[/偷笑]](https://youthlin.com/wp-content/themes/twentytwenty-child/images/smilies/偷笑.gif)
请问为什么内网的uims 不能用这种方式登录呢?是需要修改什么吗?
嗯,需要改登录地址和查询地址。
嗯,还有貌似需要在 header 里加Referer才行![[/呲牙]](https://youthlin.com/wp-content/themes/twentytwenty-child/images/smilies/呲牙.gif)
我觉得现在应该学 Python3 吧,这个与3不兼容。
目测你也是住北一?我们IP地址都是同一片哈哈
居然提供JSON接口,这个网站很强大
因为他的网页是框架式的,类似标签页的功能模块,所以数据都是json格式的
[…] 按时间顺序讲好了。 网页正文提取、中文分词。最先搜到了python版(因为之前写的Python写的吉大公网版成绩查询用python写的,所以也会用一点python了)的python-goose、python-readability,试了一下还挺准的(其实是因为网上介绍它说挺准的我才去试了一下)。不过还要java版的,又搜到了cx-extractor可能太古老了,能用,但我忘了为什么最后用的是ContentExtractor。然而这个ContentExtractor有时正文文字不太密集的话,而恰好footer里或其他地方文字更密集,那就提取不到正文了。。至于分词,是小伙伴找到的,一个牛逼的项目 https://github.com/NLPchina/ansj_seg 支持中文分词、自定义词典、词性标注等功能。 […]
phyton好火啊现在
这玩意不错,以前我也想尝试做个类似的,后来没成行。兄弟你有才。