本文介绍了在 Go 语言编程中,使用 github.com/youthlin/t 软件包实现国际化的方式,其兼容 GNU gettext 工具链。最简示例如下所示:
1 2 3 4 5 6 7 8 9 10 11 |
|
0 前言
简单理解两个概念
localization(L10n) 本地化,将软件翻译为本地语言的过程,通常是翻译人员的职责。
internationalization(i18n) 国际化,使得软件可以被本地化,通常是开发人员的职责。
国际化的一般步骤
- 开发。编写程序时,不能硬编码文本,应通过某些形式(如函数调用)获取原文对应的译文。
- 提取。将待翻译文本提取出来。
- 翻译。将提取出的待翻译文本,翻译为目标语言。
- 显示。程序运行时,在最终用户的界面中显示翻译后的本地语言。
提到国际化的话题,我第一反应想到了 GNU gettext 工具链。之前使用 WordPress (一个流行的开源博客程序) 的时候了解过,它的国际化就是使用 gettext 的形式实现的。所有需要国际化的文本只需要使用双下划线(实际是 gettext 函数的简短形式 )包裹即可,如 __('text'). 然后使用 PoEdit 等软件提取待翻译文本翻译,将翻译后的 .po/.mo 文件放在指定目录下就行了。
https://github.com/youthlin/t ,是 GNU gettext 的一个 Go 语言原生实现,而且简化了其中一些不太常用或不太好理解的用法。
1 使用方式
1.1 开发阶段标记翻译文本
go mod 引入:
1 2 3 |
|
代码中使用:
1 2 3 4 |
|
以上是最简单的用法,第一步加载翻译文件,第二步获取译文。默认会自动获取系统语言,加载路径支持文件夹、.po 文件、.mo 文件,也可以使用 LoadFS 加载 embed.FS. 其他 API 在下文介绍。
1.2 提取待翻译文本
代码中的待翻译字符串,可以直接使用 GNU gettext 工具链提取,也可以使用 PoEdit 工具提取。因为 Go 的语法和 C 语言类似,所以可以直接按 C 语言提取。
在 PoEdit 的 设置-提取器 中新增一个提取器:xgettext -C --add-comments=TRANSLATORS: --force-po -o %o %C %K %F, 从源代码中提取,关键字设置为 T;N;N64;X:2,1c;XN:2,3,1c;XN64:2,3,1c 即可:
1
|
|
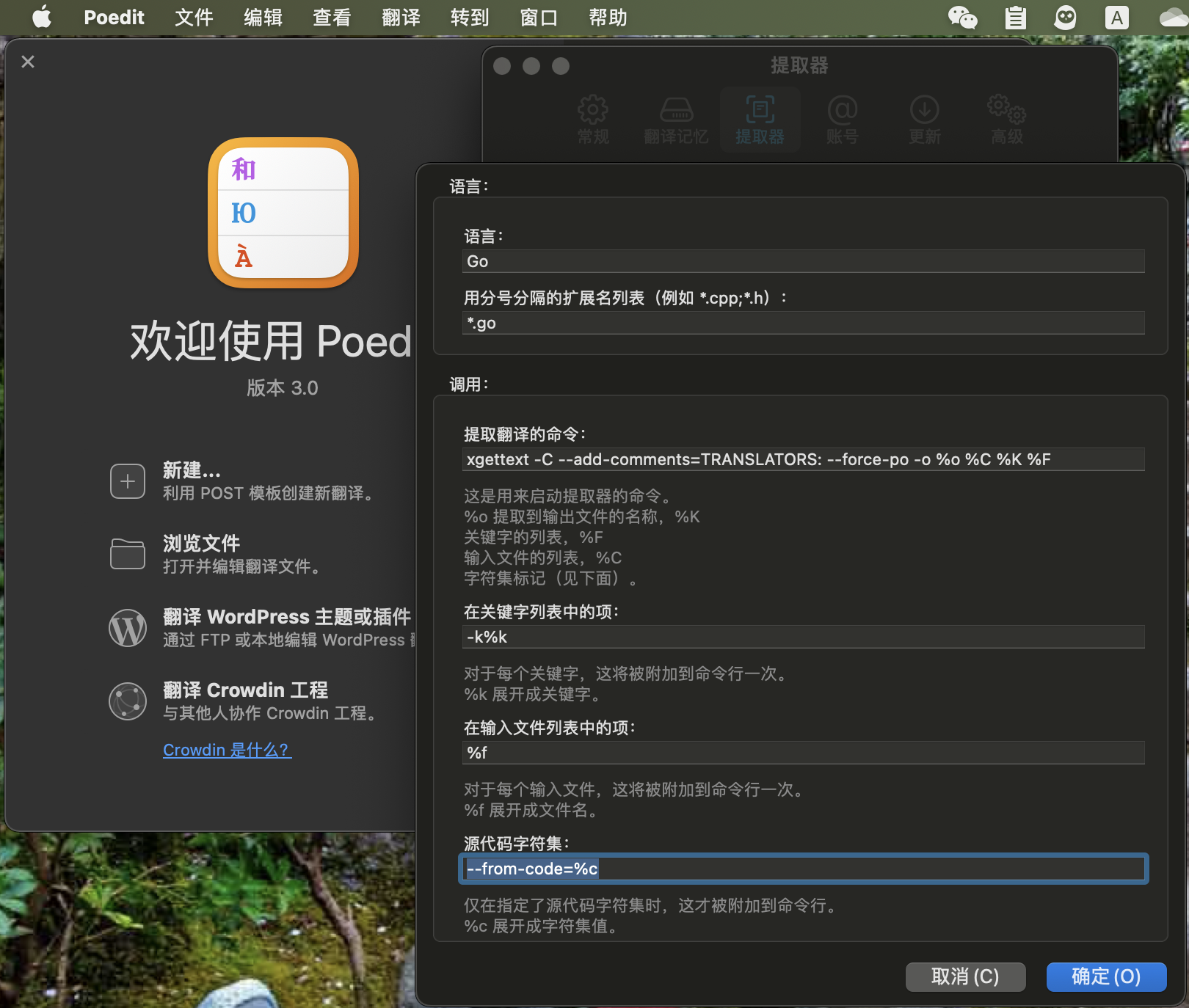
在 PoEdit 中设置好提取器之后,直接新建一个翻译,选择翻译语言后,选择从源代码中提取:
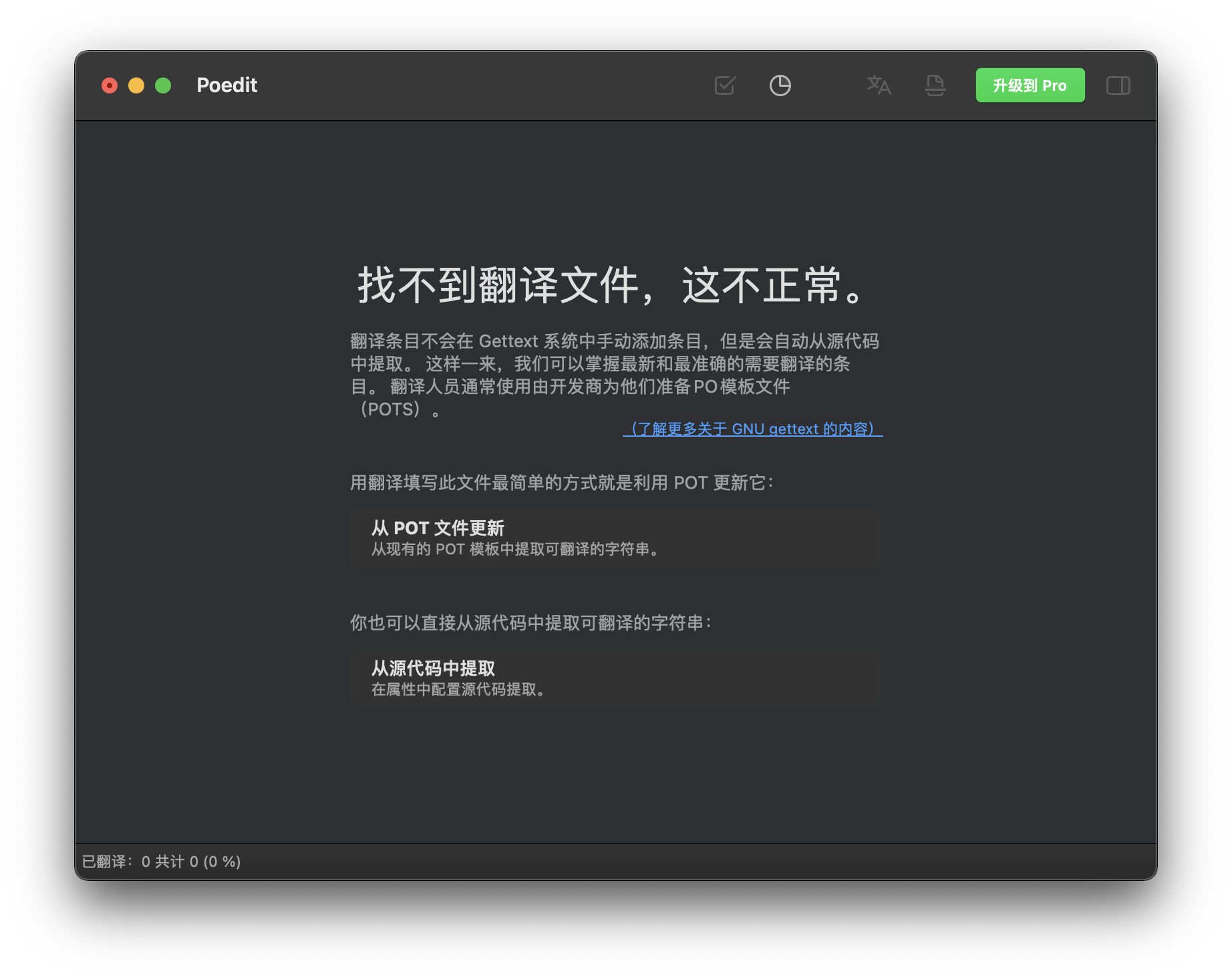
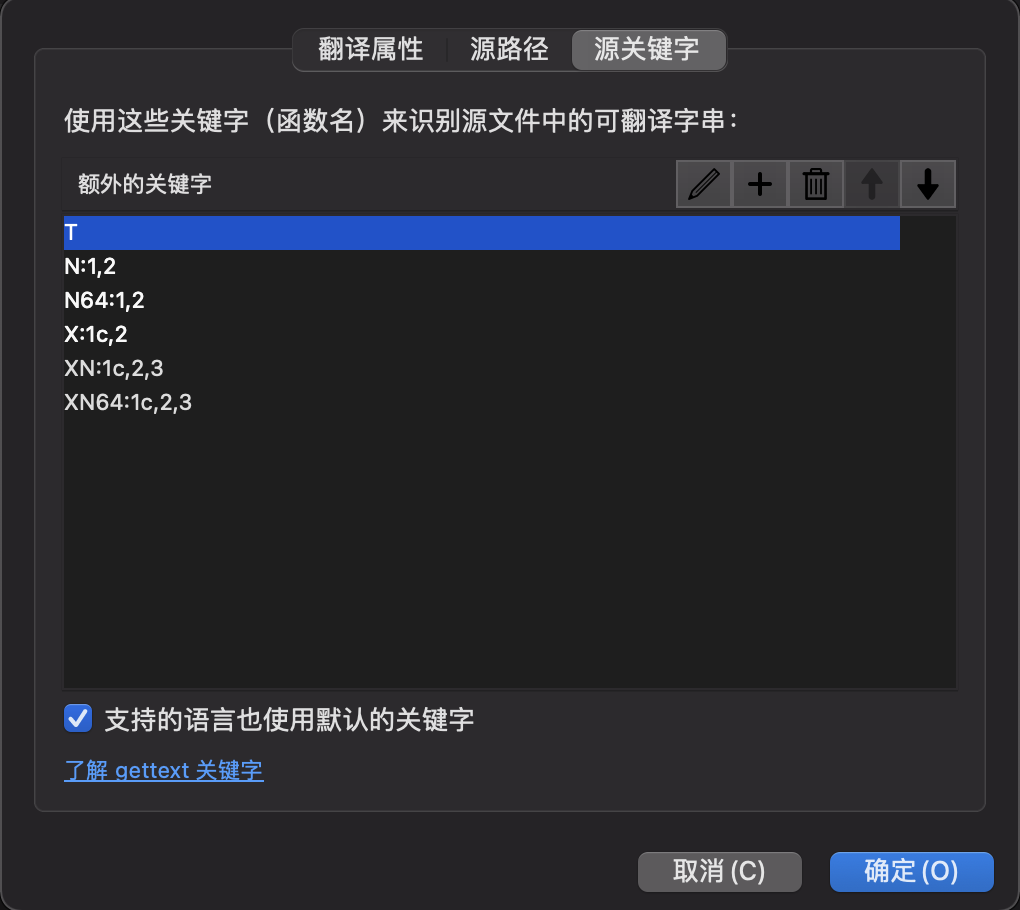
然后设置源代码路径和提取关键字。关键字设置中,冒号之前是函数名,冒号之后是参数索引。函数只有一个参数可以省略索引,表示待翻译文本;冒号后有两个数字,表示单数和复数的原文;冒号后有三个数字,带 c 的索引表示上下文,另外两个表示单数和复数:
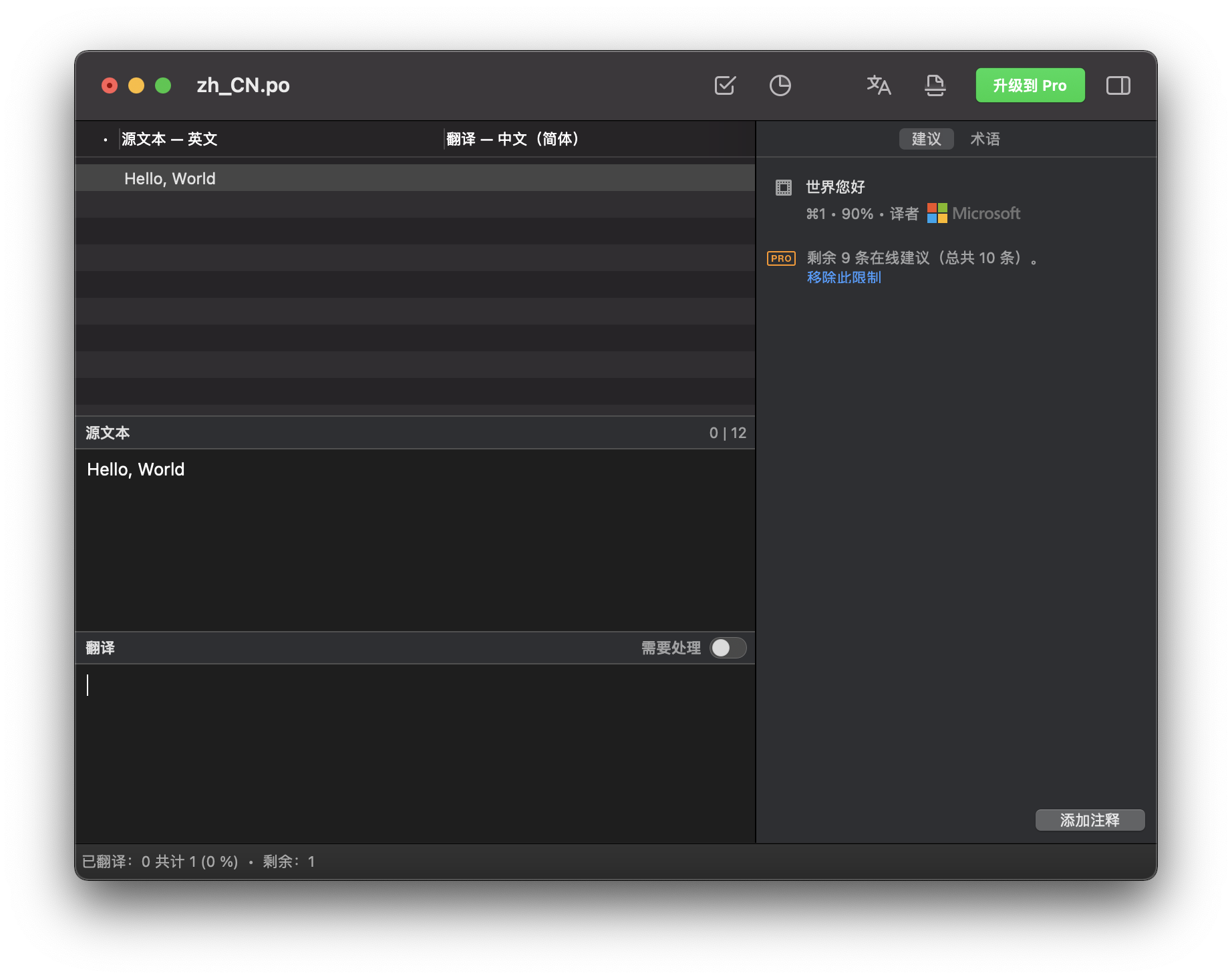
确定后,就能看到提取到的待翻译文本了:
不过,模板文件中的字符串就不能使用这种方法了,所以写了一个配套的提取工具:xtemplate
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
如果模板文件更新了,需要使用 xtemplate 提取 .pot 文件后,再使用 GNU gettext 的 msgmerge 工具 merge 新旧 pot 模板文件。
1.3 本地化翻译
理论上可以使用任意的文本编辑器从 pot 模板文件创建 po 翻译文件,但是我们有 PoEdit 等强大的工具,应该使用 PoEdit 等工具来做这件事。
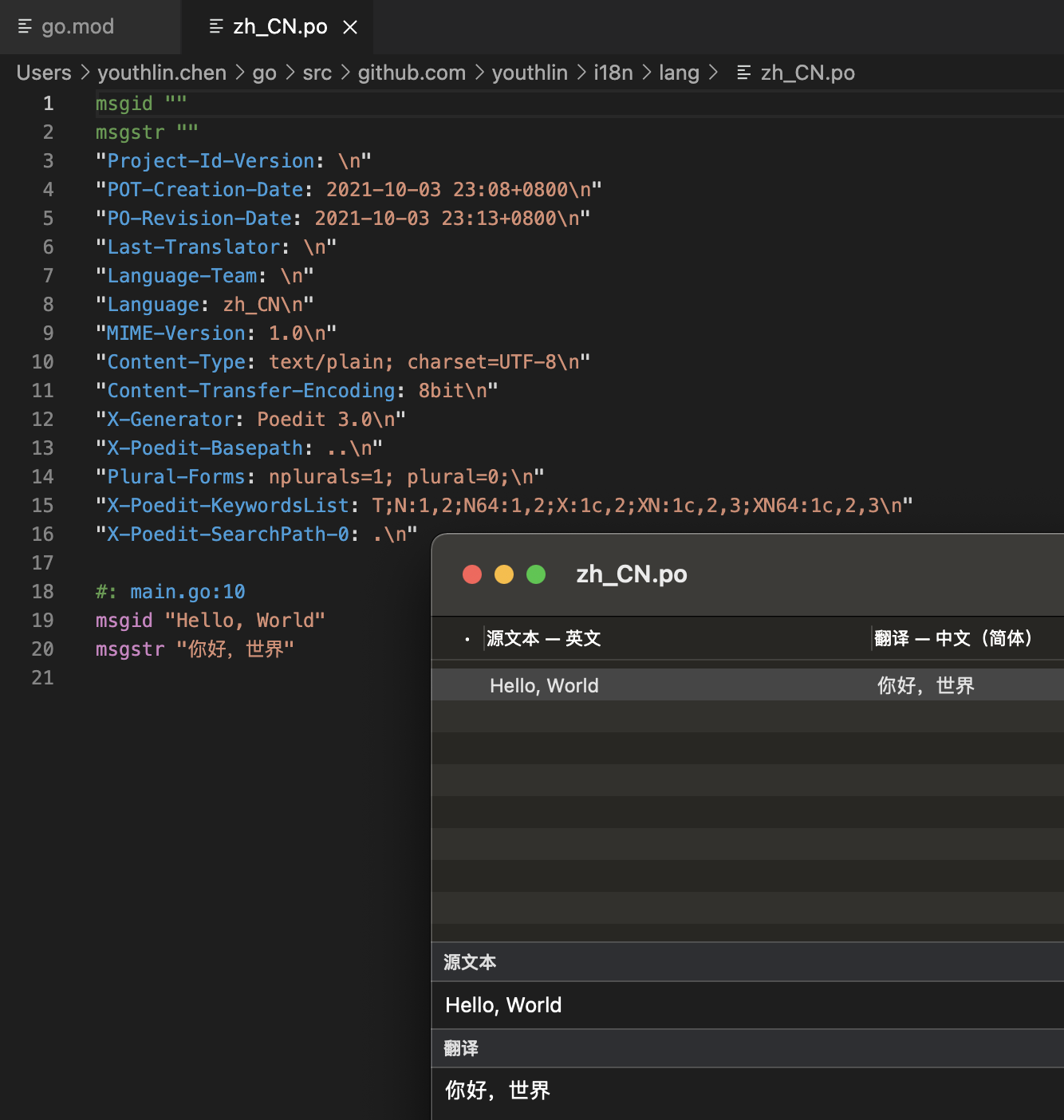
1.4 显示译文
将 po 翻译文件放在程序中指定的 Load 路径 ./lang,然后运行程序,即可看到译文:
1 2 |
|
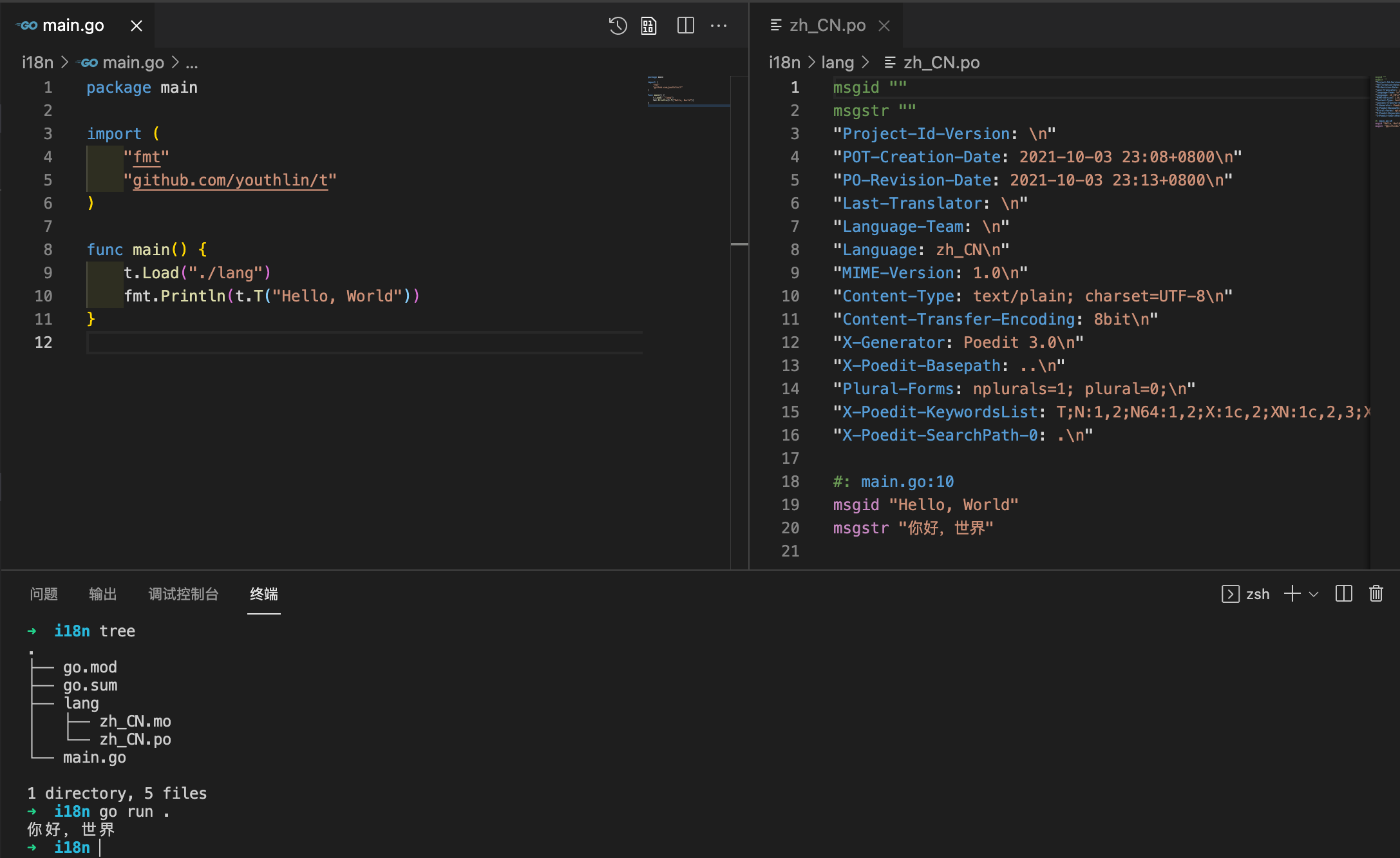
2 API
1 2 3 4 |
|
T 对应 gettext , 是最常用的直接翻译的方法;N 对应 ngettext,用于单复数翻译;X 对应 pgettext 用于上下文相关的翻译,XN 则是上下文相关的单复数翻译,对应 npgettext. 四种形式均支持传入格式化模板和参数。如:
1 2 |
|
单复数翻译,是指对不同的数字,目标语言可能有不同的形式,如英文中有两种复数形式:单数和复数。所以 t.N 方法使用参数 n 来选择目标语言中的哪一种复数形式,如果同时要格式化 n 的话,还需要在 args 参数中再次传入 n.
上下文相关翻译,可以指明原文的上下文,以便译者参考。如
1 2 |
|
2.1 domain
不常用,只是按惯例实现了文本域。一般情况下不用关心文本域,直接使用默认的即可。在 PHP 博客程序 WordPress 中,文本域用来区分不同的主题/插件,以免与博客主程序相冲突。所以对于支持多模块的项目来说比较有实用意义。用法:
1 2 3 4 5 |
|
2.2 locale
默认情况下不指定 locale 会自动检测系统的语言(使用的是 github.com/Xuanwo/go-locale 这个库)。对命令行或桌面等单机程序很有用。如果是 web 应用,应该是不同用户使用不同语言更合理。如果用户手动选择语言,可以这样实现:
1 2 |
|
如果需要自动检测用户语言,比如可以根据浏览器标头判断用户偏好,可以这样做:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
还可以在 text/html 模版中使用。将 t := t.L(userLang) 关联到模板中,然后在模板中使用即可:
1 2 3 |
|
2.3 更多示例
https://github.com/youthlin/examples/tree/master/example-go/i18n 仓库中有 cli, gui, web 三种场景的示例。
3 开发过程的问题
3.1 fmt 格式化时,参数个数不对应会报错
1 2 3 |
|
解决方式是指定位置占位符(参数索引):
1 2 |
|
所以使用自定义 Format 包装一下格式化功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
3.2 获取系统语言
找到一个第三方库兼容多平台获取系统默认语言:github.com/Xuanwo/go-locale
3.3 复数解析
gettext 文档 例举了多种复数表达式,如中文等东亚语言,只有一种复数形式: Plural-Forms: nplurals=1; plural=0; 英文有两种复数形式:nplurals=2; plural=n != 1; 拉脱维亚语有三种复数形式:nplurals=3; plural=n%10==1 && n%100!=11 ? 0 : n != 0 ? 1 : 2;
复数形式有多种,所以需要能够解析复数表达式。我使用的是 antlr(import "github.com/antlr/antlr4/runtime/Go/antlr")解析出语法树,然后自己遍历语法树结合一个栈做表达式计算。语法文件如下:plural/plural.g4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
3.4 遍历 FS
为了能够兼容 embed.FS,项目中有 LoadFS(fs.FS) 的方法,并且把普通的 Load(path) 也转为了 FS 的统一形式。标准库中有个 os.DirFS 方法,打开文件直接打开的是 dir/name 路径,但是为了统一加载文件夹和单个文件的逻辑,使用的是 fs.WalkDir(fs, root, fn) 方法遍历 FS,需要传入遍历起点路径,项目中使用的是 ".", 遍历时就是 xxx.po/. 遍历时报错 stat testdata/zh_CN.mo/.: not a directory
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
使用 filepath.Join 遍历单个文件模拟的 fs 时,起点路径传入 "." 也不会有问题了:zh_CN.po/. 会被处理为 zh_CN.po.
4 go 语言的其他实现
Go 语言的官方实现,golang.org/x/text/message 包,使用方式:
- 安装
golang.org/x/text/cmd/gotext - 将所有需要翻译的文本使用
message.NewPrinter来打印,或者运行gotext命令会自动将fmt.Printf更改为 message.Printer 的调用 - 使用
gotext extract提取翻译文本 - 将翻译文件给到译者进行翻译
- 将翻译后的文件注入到程序中
- 从第二步重复
缺点:无法复用现有的 GNU gettext 工具链,默认提取出来的文件是 json 格式,还需要额外学习其结构,以及单复数表示,参数格式化形式等方方面面。(文档中还专门有个视频链接介绍这个包:https://www.youtube.com/watch?v=uYrDrMEGu58)
https://github.com/nicksnyder/go-i18n 1.8k 赞,也是重新造了一套轮子,和现有的 gettext 工具脱节,默认提取为 toml 格式的文本文件。我想找个兼容 gettext 格式的库,这个一开始就没找到,是后来在漩涡的博客文章中看到的。
使用 gettext 关键字搜索 Go 语言仓库:
https://github.com/gosexy/gettext 50+ 赞,使用 CGO 底层直接调用 GNU 的 gettext 工具,这个不是 Go 原生的实现,就没继续研究。
https://github.com/leonelquinteros/gotext 300+ 赞,貌似一直在活跃开发中。看起来功能挺全的,但是好像不能检测系统语言,需要手动设置。
https://github.com/chai2010/gettext-go 70+ 赞,需要手动设置语言;复数表达式是枚举出来的。
Reader Echoes
No comments yet