在图书馆看到关于 Hadoop 的书,刚好有空,就借回来了看看。然后在寝室尝试搭建环境,用了一天才弄好。
Hadoop 的运行模式有 单机模式、伪分布式模式、完全分布式模式。我选择的时完全分布式模式安装。
因此需要多台机器。但哪来的多台机器呢,当然是虚拟机啦。
因为 Hadoop 只能运行在 *nix 环境中,因此我在 Ubuntu 中又用 VirtualBox 安装了两台虚拟机。一台作为 master, 一台作为 slave1.
因为怕搞坏宿主机器,因此没在物理机上折腾。集群,通常是有好多台机器的,但我内存才 6G 还是就开两台吧。
首先安装虚拟机都很容易,就不说了。需要注意的就是用户名、机器名和网络配置。
据说 Hadoop 需要集群中机器的用户名一致,因此安装时用统一的用户名密码即满足有求又好记。
主机名,master 就设置为 master, slave 就设置为 slave1. 如果有更多 slave,数字递增即可。主机名只是助记用的,不用太在意这些细节。
然后就是网络配置。我们需要实现的目标有:
1. 各虚拟机间可互相访问
2. 虚拟机和主机可互相访问
3. 虚拟机可上外网
为了实现第三点,最方便的方法就是使用“网络地址转换(NAT)”这种方式。
为了实现第一点和第二点,还需要增加 “仅主机(HostOnly)”方式。
VirtualBox 的虚拟机有多种网络配置模式,包括:桥接、网络地址转换(NAT)、NAT、仅主机等。
桥接方式是虚拟出一块网卡,虚拟机内使用这个虚拟网卡,相当于一台物理机配置网络。但我们学校一人一个 IP 地址,网络也需要认证登录,因此并不适用。
网络地址转换(NAT)是默认的网络配置,这样可以使虚拟机上网,也不要配置 IP,动态分配 DHCP 的 IP 地址,相当于虚拟机是宿主的一个程序。
NAT 方式,据说是上一个模式的升级版,没试过(需要在 VB 全局设置里配置网卡)。
仅主机模式,虚拟出一个网卡,宿主和虚拟机都可以连接,这样宿主和虚拟机就在同一个网络中可互相访问了。
我使用的方式是,在虚拟机的「管理」-「全局设置」-「网络」中,选择「仅主机网络」,没有配置就添加一个,有就双击查看详情,记下IP地址。
默认是 192.168.56.1 你也可以改为 192.168.1.1 这种。DHCP 选项卡不勾选。
然后这样宿主就自动连接上这个虚拟网卡了,Ubuntu 菜单栏会有一项显示「设备未托管」的网络就是这个。因为你的IP就是刚刚记下的,不需要再在「编辑连接」里配置了。
在虚拟机关闭状态或刚新建还没启动时,配置他的网络。选择要配置的虚拟机,「设置」-「网络」:
网卡一:启用网络连接,选择「网络地址转换(NAT)」。
网卡二:启用网络连接,选择「仅主机(HostOnly)适配器」,界面选择刚刚全局添加的那个名称。
启动虚拟机后,在其中可以看到两个网络连接,在右上角的菜单栏中点击选择「编辑连接」
「以太网」选项卡选择网络接口,新版本的Ubuntu不是eth0/eth1这种名称了,是 enp0s3/enp0s8类似的名称,数字小的一个是网卡一,另一个是网卡二。
在网卡一中,我们选择的是 NAT 模式,那么,在 IPv4 选项卡,就只需要选择 DHCP 就行了,不用配置 IP 地址(自动分配10.0.2.x)。这个是虚拟机上外网的网络。
在网卡二中,我们选择的时仅主机模式,在 IPv4 选项卡中,需要配置静态 IP(网关可以不用配置),用于各个机器间互相访问。这个是宿主和虚拟机之间的局域网。
还需要在IPv4选项卡中的「路由…」按钮中勾选「仅将连接用于相应的网络上的资源」这样当两个网络同时启用时,访问外网就不会用网卡二的网关了。否则可能访问外网使用网卡二的网关192.168.56.1,那么将不能访问外网。

现在,你可以在虚拟机(192.168.56.2)中ping通外网(如youthlin.com)、其他配置好的虚拟机(192.168.56.3)、宿主机(192.168.56.1)。
然后就是准备安装 Hadoop 了。
- Open-SSH
- JDK7+
- Hadoop2.7.3
ssh 就是配置免密码登录。
ssh-keygen -t rsa
生成公钥私钥密钥对,把公钥 id_rsa.pub 导入目标主机的 authorized_keys 文件中,那么本机就可以免密码登录目标主机。
Hadoop 2.7 需要 JDK7+ 版本,我是在 Oracle 网站上下载 JDK 然后解压的。只需在 /etc/profile 要配置 JAVA_HOME 就可以了。
Hadoop 我下载的是当前 2.7.3 版本,解压在 /opt/ 文件夹下。
chown -R xxx /opt
xxx 为你需要的用户名,意思是把 /opt 文件夹授权给 xxx 用户。
配置文件全在 $HADOOP_HOME/etc/hadoop下
export JAVA_HOME=xxx
export HADOOP_HOME=xxx
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
这三个环境变量在 profile 里也要配置一下,把 $JAVA_HOME/bin、$HADOOP_HOME/bin 加入 PATH,注销再登录生效。
core-site.xml
hdfs-site.xml
mapred-site.xml.template
slaves
这几个文件具体配置自行搜索吧,我也不太确定咋配。可看下方参考链接。
先在 HADOOP_HOME 下新建了 tmp、name、data 文件夹,hadoop.tmp.dir 设为 tmp,dfs.namenode.name.dir 设为 name的路径,dfs.datanode.data.dir 设为 data的路径。暂时没有用到 yarn.xml 等以后搞明白了在研究……
所有机器都这样配置。然后就算配置好了环境~
准备启动之前需要先格式化 HDFS. 这是 Hadoop 用的分布式文件系统,理解为 NTFS、ext4 之类的就行了,只不过 HDFS 里的文件时存在多台机器上的。
hdfs namenode -format
Exiting with status 0就表示执行成功了。
启动使用的命令在 $HADOOP_HOME/sbin 下,用 start-dfs.sh 和 start-yarn.sh 启动 Hadoop
hdfs dfs -ls
hdfs dfs -put
hdfs dfs -cat
用于列出HDFS里文件、上传本地文件到HDFS、输出HDFS里文件内容。
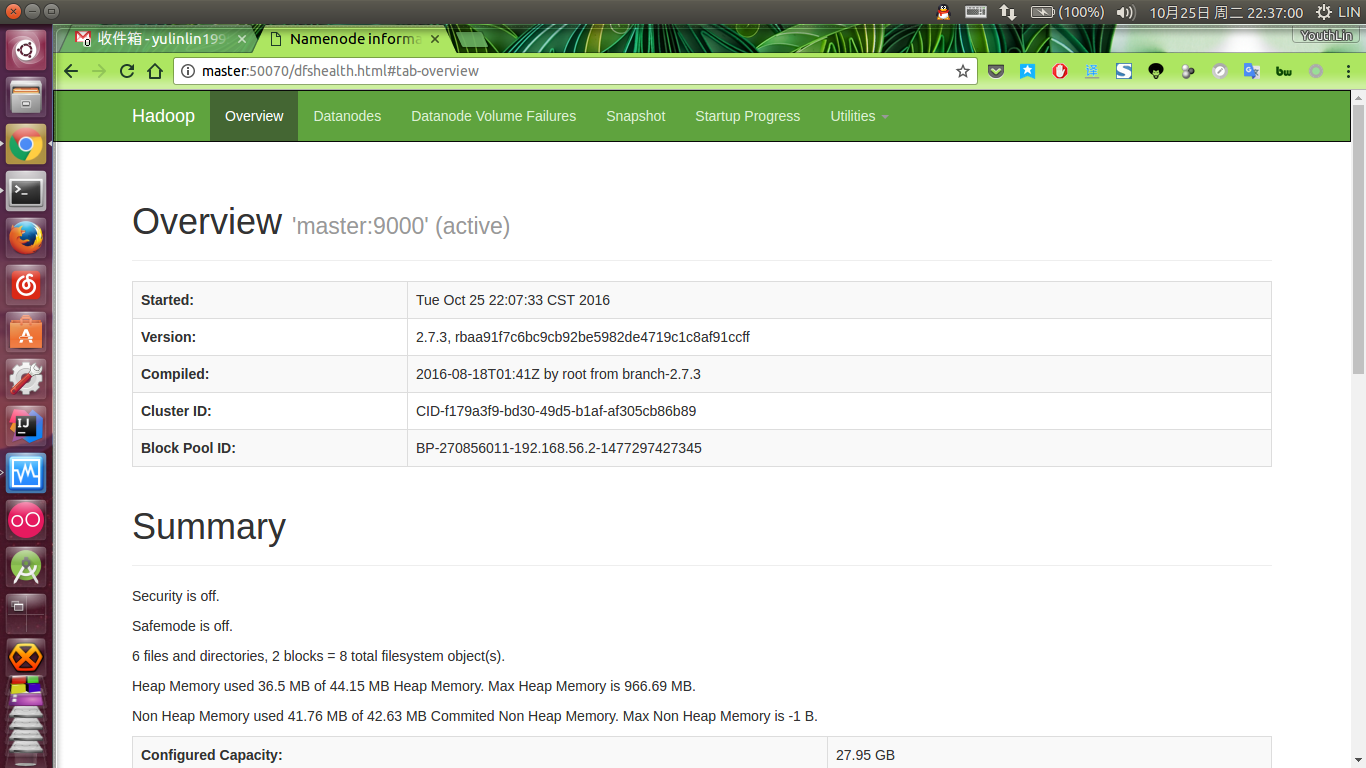
测试安装是否成功用 WordCount 检测。(此时可以访问 http://master:50070/ 为了方便可以把 master/slave1 的 IP 放在/etc/hosts 里)
首先在 master 里随便准备一个文本文件,比如叫做 words,内容就是几个单词。
然后再
hdfs -dfs -put /path/to/words /test/words
这样就把 words 文件放入 HDFS 文件系统了。
在 HADOOP_HOME 执行:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /test/words /test/out
记执行单词计数统计程序,/test/words 为输入文件,/test/out 为输出目录,其中输出目录的父目录必须存在,否则报异常,slave 里 hadoop-env.sh 没配置 JAVA_HOME 也会报异常。退出码为 0 表示执行成功。
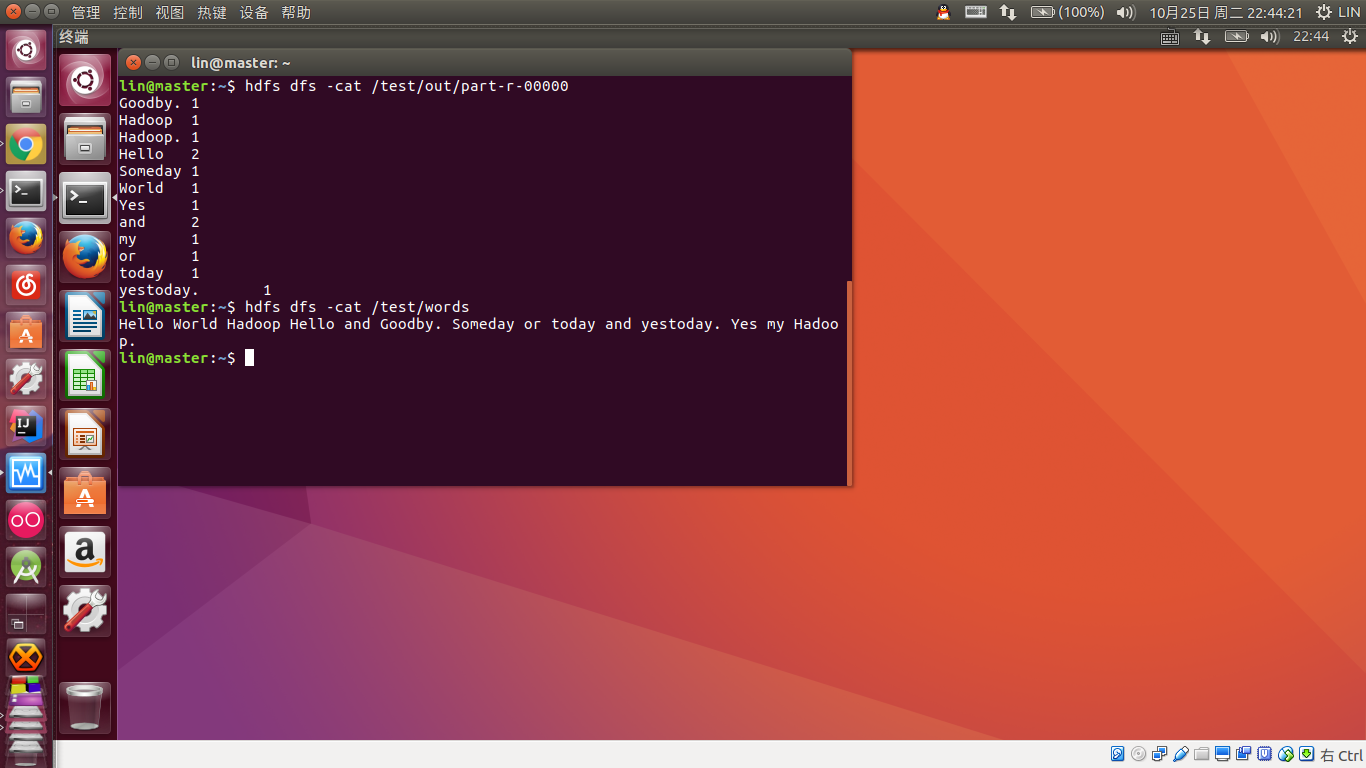
这样就算安装成功启动成功了,jps 命令可以看到运行中的 Java 进程。下一步有空的话再看书学习~
参考文章:
- Virtualbox 虚拟机网络配置 (NAT + Host-only – Bridged)
- VirtualBox 下虚拟机和主机内网互通 + 虚拟机静态 IP 的网络配置
- ubuntu 中 ssh 无密码配置 ,hadoop 节点之间无密码登录
- 【大数据】Linux 下安装 Hadoop(2.7.1) 详解及 WordCount 运行
声明
- 本作品采用署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。除非特别注明, 霖博客文章均为原创。
- 转载请保留本文(《Hadoop 集群搭建》)链接地址: https://youthlin.com/?p=1351
- 订阅本站:https://youthlin.com/feed/
“Hadoop 集群搭建”上的1条回复
然后你挑了最牛逼的完全分布式。。。